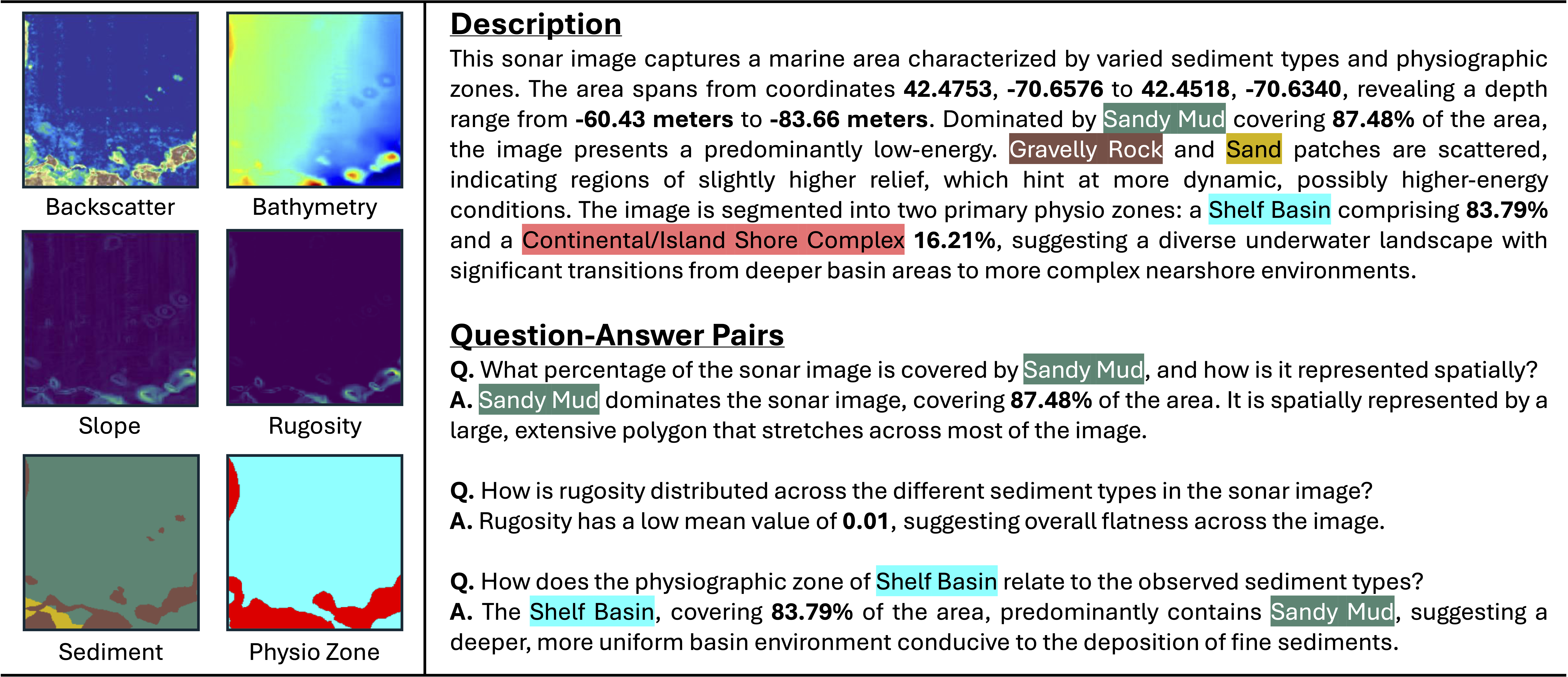
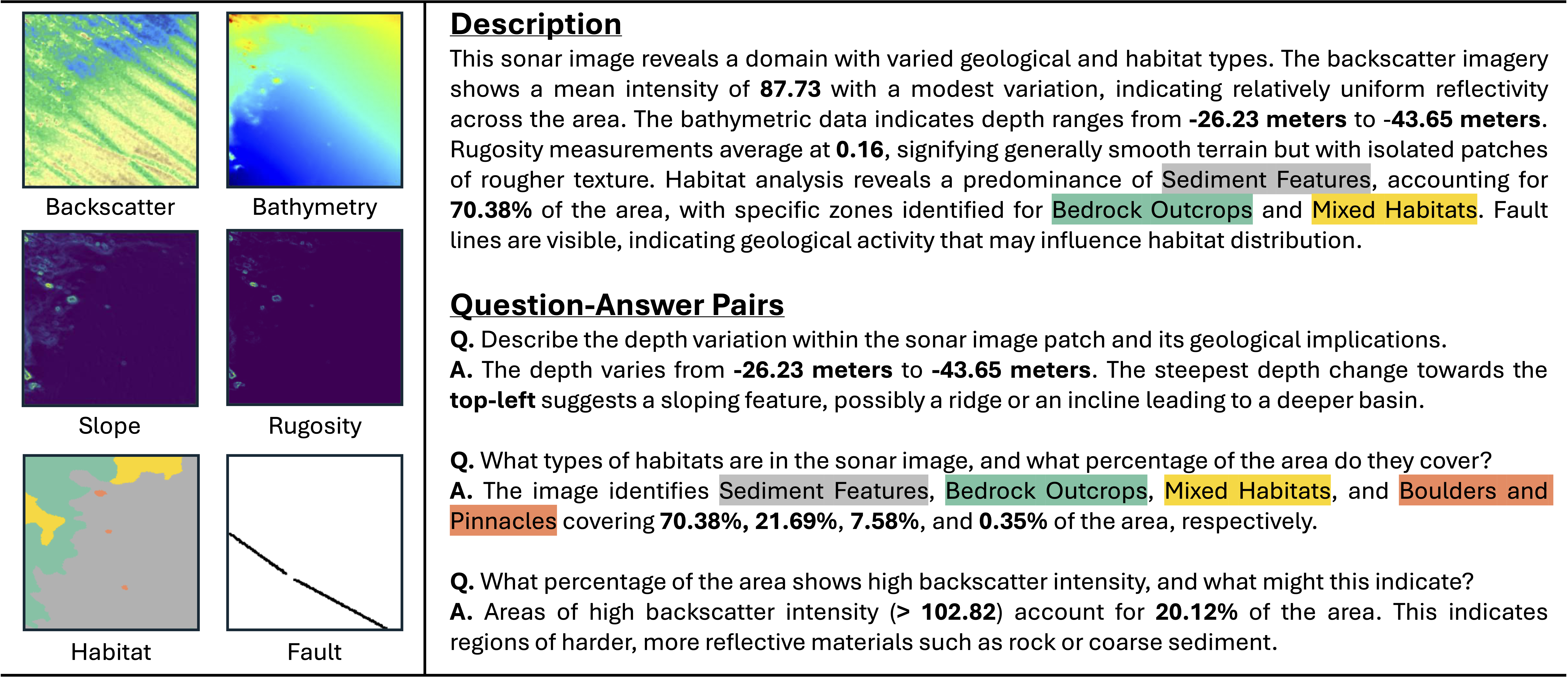
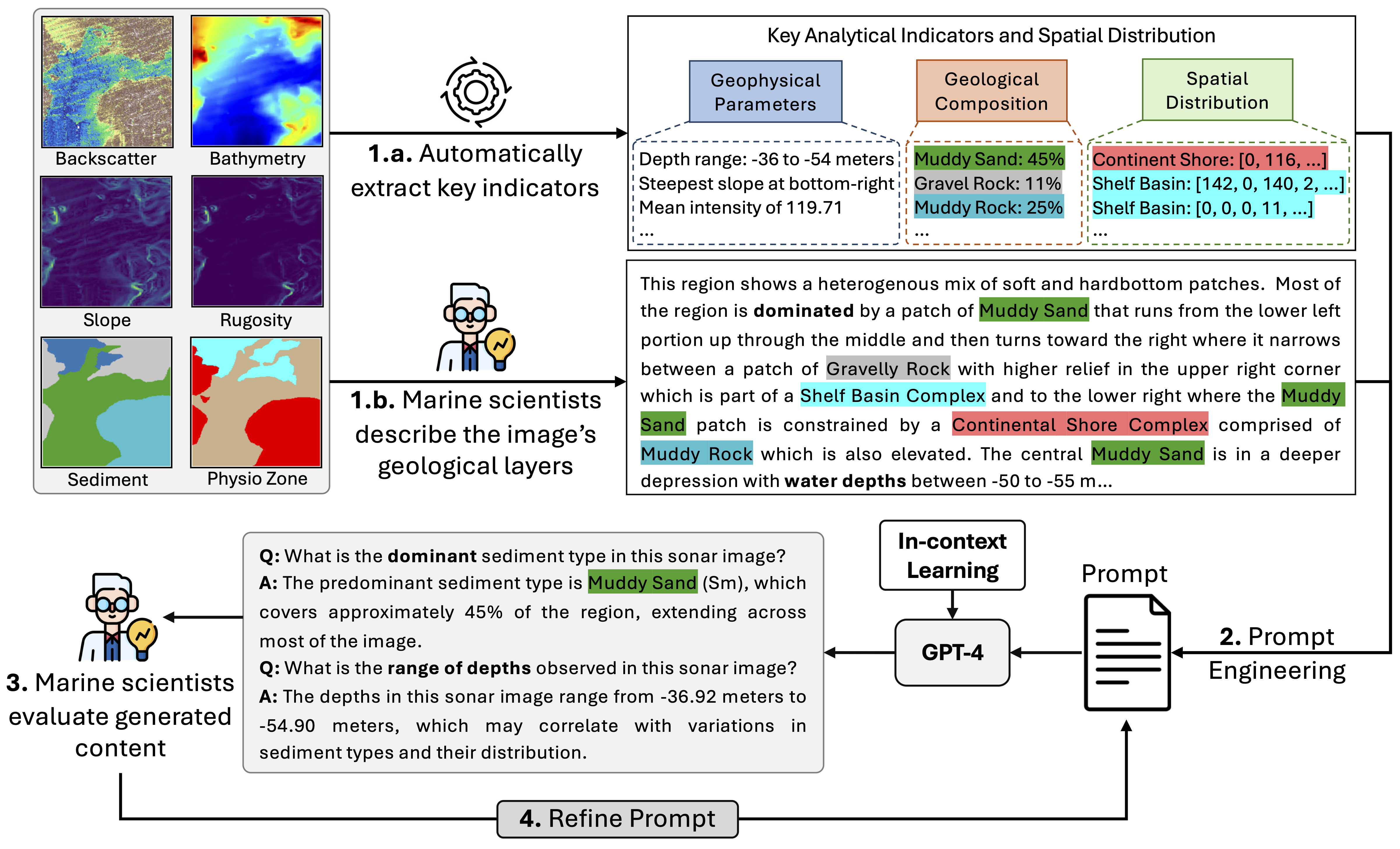
What is Seafloor Mapping?
Seafloor mapping is the process of creating detailed maps of the ocean floor to understand its shape, depth, and the types of materials that cover it, like sand, rocks, or mud. This information helps scientists and industries make decisions about marine life conservation, offshore construction, and resource exploration.
The photo shows a tow ship and an autonomous underwater vehicle (AUV) capturing detailed images of the seafloor's texture (backscatter) and depth (bathymetry) using multi-beam echosounders or side-scan sonar.